一、引入大小端
在我们经常使用的VS2019编译器使用过程过,我们经常会查看变量的内存
例如
1 | int main() |
在计算机系统中,数值一律用补码来存储,主要原因是:
- 统一了零的编码
- 将符号位和其它位统一处理
- 将减法运算转变为加法运算
- 两个用补码表示的数相加时,如果最高位(符号位)有进位,则进位被舍弃
10
10的原码反码补码都是
0000 0000 0000 1010
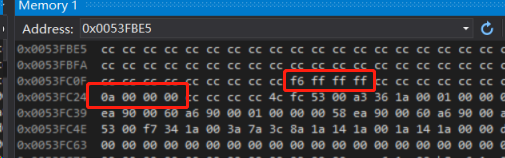
内存就是:0x 0000000a
观察vs2019编译器中的内存字节序如下
由上也可以看出栈的生长方向是向下的,是向着内存地址减小的方向增长
-10
原码 10000000 00000000 00000000 00001010
反码 11111111 11111111 11111111 11110101
补码 11111111 11111111 11111111 11110110
内存:0xff ff ff f6
二、什么是大小端?
- 大端(存储)模式:是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中。
- 小端(存储)模式:是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。
通俗来说:
- 倒着存:小端
- 正着存:大端
三、为什么会有大端和小端?
为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
四、测试当前机器的字节序
我们知道存储方式无非大端存储和小端存储两种方式
因此我们可以用1来进行举例,我们知道1在内存中
1的补码:00000000 00000000 00000000 00000001
无非以下两种存储方式:
小端:01 00 00 00
大端:00 00 00 01
因此我们可以发现,我们可以通过第一个字节来进行判断,如果是1,则是小端存储;如果是0则是大端存储。
代码实现:
1 | int main() |
其他平台的大小端测试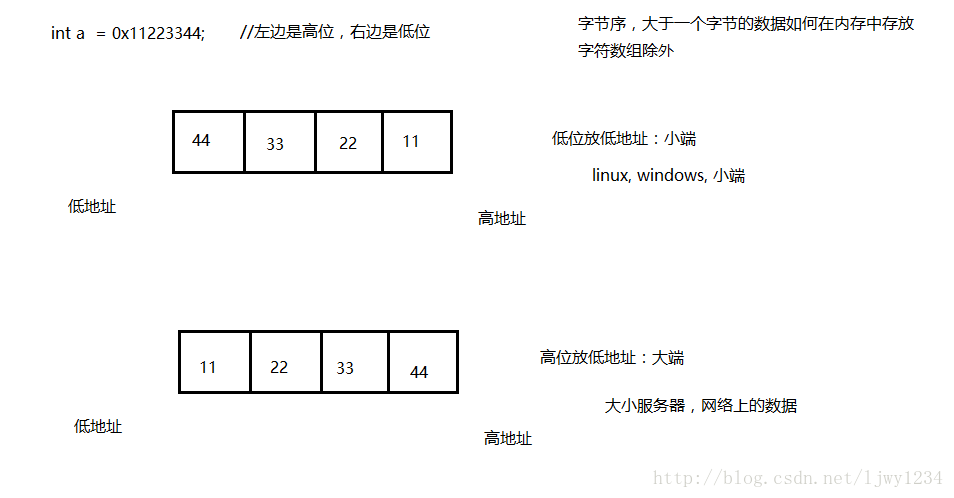
参考链接:
https://blog.csdn.net/qq_58325487/article/details/122293276
https://blog.csdn.net/weixin_44718794/article/details/106252940

